本節の目的
WWW(World Wide Web)の要素技術の概略とWWWの仕組みを理解することです。
ハイパーテキストとWorld Wide Web(WWW)
 World Wide Webは「ハイパーテキスト(Hyper Text)」と呼ばれる文書の仕組みをインターネット上で実現したものです。自己完結した通常のテキスト文書とは異なり、ハイパーテキストには文書同士を関連づける仕組みが備わっています。文書同士を関連づける仕組みは「ハイパーリンク(Hyper Link)」と呼ばれ、文書のある部分(単語や文章の一部分)から他の文章を参照することができます。この仕組みによって関連する情報を効率よく整理・閲覧することが可能となりました。皆さんは、既にWebブラウザのリンク(ボタン)をクリックして、複数のWebページ(文書)が連結されているのを利用していますよね。
World Wide Webは「ハイパーテキスト(Hyper Text)」と呼ばれる文書の仕組みをインターネット上で実現したものです。自己完結した通常のテキスト文書とは異なり、ハイパーテキストには文書同士を関連づける仕組みが備わっています。文書同士を関連づける仕組みは「ハイパーリンク(Hyper Link)」と呼ばれ、文書のある部分(単語や文章の一部分)から他の文章を参照することができます。この仕組みによって関連する情報を効率よく整理・閲覧することが可能となりました。皆さんは、既にWebブラウザのリンク(ボタン)をクリックして、複数のWebページ(文書)が連結されているのを利用していますよね。
ハイパーテキストの仕組み自体は古く、1960年代にはHypertext Editing SystemやNLSシステムとして実現されています。しかし、この当時コンピュータは一部の研究機関しか所有しておらず、一般に普及するのはもっと後のことです。1990年にCERN(欧州原子核研究機構)のティム・バーナーズ・リーにより、現在のWorld Wide Webの仕組みが実現されます。当初World Wide Webは研究者同士が情報を共有するための仕組みとして作られ、テキスト文書しか扱うことができませんでしたが、すぐに画像・音声など様々な素材を扱うための仕組みが追加され、インターネット・パソコンの普及とともに全世界に普及しました。
World Wide Webとは直訳すると「世界中に張り巡らされたクモの巣」の意味ですが、世界中のハイパーテキスト文書がハイパーリンクでつながった様子を形容しています。 World Wide Webでは「重要なページほど他のページから参照される」という傾向があり、このことを利用して高性能な検索エンジンの開発に成功したのが米Google社です。ハイパーリンクの仕組みが無ければ、インターネット上の膨大な情報を現在のように便利に使うことはできなかったでしょう。
World Wide Web(WWW)を構築している技術と構成要素
皆さんが親しんでいる World Wide Web (WWW, Web, ウェブ)は、比較的簡単な仕組みで成り立っています。
WWWは、基本的に以下の技術と構成要素から成り立っています。
- URI (Uniform Resource Identifier)
- HTML (HyperText Markup Language)
- Webブラウザ (Web Browser)
- Webサーバ (Web Server)
URIは「インターネット上のリソース(ファイル、画像等)」を指定するための書式のことで、ハイパーリンクで参照する文書を指定するときに使います。HTMLはハイパーテキスト文書の記述に用いられる言語のことで、ハイパーリンクもHTMLを使って記述します。
URI (Uniform Resource Identifier)
World Wide Webでハイパーリンク先の文書を指定するには、「どのコンピュータに入っているどの文書(画像,音声,etc)か」を指定する必要があります。
インターネット上のコンピュータを指定するには、FQDN名を使います。FQDN名を使えば、インターネットにつながれた世界中のコンピュータの中から、ある1台を間違いなく指定することができますね。文書を指定するには、そのコンピュータに入っているどの文書かを「ファイルの保存場所」と「ファイルの名前」を組み合わせた「パス名」と呼ばれる書式で書きます。
この考えをもとに、『インターネット上にあるすべてのリソース(資源、ファイル)を、統一的に一意な名前で呼ぶ』ために考えられた仕組みがURIです。
![]() 「パス名」については、この後の演習で詳しく説明していきます。
「パス名」については、この後の演習で詳しく説明していきます。
![]() 「FQDN名」については、この後の(参考)で説明します。
「FQDN名」については、この後の(参考)で説明します。
URIは、「スキーム」「サーバ部」「パス部」で、構成されています。
例えば、「www.kumamoto-u.ac.jp」というコンピュータの「/visitor」というフォルダに保存された「zaigakusei.html」という文書を指定するURIは、
http://www.kumamoto-u.ac.jp/visitor/zaigakusei.html
となります。 このURIでは3つの構成要素は、次のようになります。
| スキーム (プロトコル,手順) |
http |
|---|---|
| サーバ部 | www.kumamoto-u.ac.jp |
| パス部 | /visitor/zaigakusei.html |

それぞれの構成要素は、おおよそ以下のようなことを表わしています。
| スキーム (プロトコル、手順) |
URIが、どのような仕組みで名前をつけるのかを表わします。これにより、リソース(資源、ファイル)を取得する手順(プロトコル)が決まります。代表的な http (HyperText Transfer Protocol) は、後述するHTMLなどの文書を受信するときに用いる(通信)手順です。 |
|---|---|
| サーバ部 | リソース(ファイル)が格納されている(リソースを提供してくれる) マシン(PCを含む)を表わします。 |
| パス部 | サーバ上のリソース(ファイル)を表わします。 リソースは通常、リソース(ファイル)が格納されている階層的なディレクトリ(フォルダ)名と、 狭い意味のリソース(ファイル)名を組み合わせた、「パス (path)」で表わします。 |
![]() URIは、リソースの「場所」を指定するURL (Uniform Resource Locator) と、「名前」を指定する URN (Uniform Resource Name) を合わせた概念になっています。ただ、URNが現実的に利用可能ではないので、URLとほぼ等価です。
URIは、リソースの「場所」を指定するURL (Uniform Resource Locator) と、「名前」を指定する URN (Uniform Resource Name) を合わせた概念になっています。ただ、URNが現実的に利用可能ではないので、URLとほぼ等価です。
URI = URL + URN ≒ URL
HTML (HyperText Markup Language)
HTMLとは、『文書の各部分を意味の塊(かたまり)として考え、意味の塊を「タグ」で囲んで表現する (マークアップ(Markup)する) 文書記述言語の一種』です。
「タグ(tag)」というのは、もともと「荷札」や「値札」のことですが、ここでは、「< >で囲まれた決まった文字の並び」のことです。このタグにより、文書の構成を指定したり、表示形式を指定したりします。
また、「文書記述言語」というのは、コンピュータ(PC)が理解できる言語(言葉)ですが、いわゆる「プログラム言語」のようにコンピュータに計算などの処理をさせるのではなく、作者の意図した文書の構造を表現するための言語です。
つまり、HTMLをもう少し具体的に言うと、 『複数の文書を相互に連結する機能をもち、 タグにより文章各部の意味付けを行うWWW用に開発された文書記述言語』 ということになります。
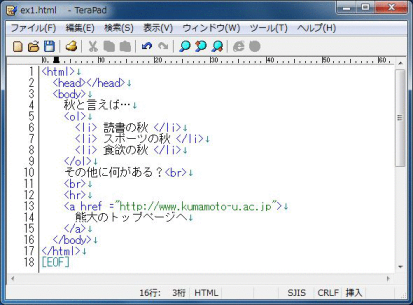
下図は、HTMLファイルのサンプルです。本来の文章の他に、 < > で囲まれたタグを含んでいることが分るでしょう。このHTMLファイルをWebブラウザで表示すると、そのタグは表示されず、タグの意味する形式で本来の文章がレイアウトされることになります。
マウスポインタを下図の上に移動すると、そのHTMLファイルをWebブラウザ(Firefox)で表示した図に変わります。Webブラウザで表示すると、< >で囲まれたタグが消えて、箇条書になったり、線になったりしていることを確認して下さい。
Webブラウザ
『言わずとしれた、Firefox や Internet Explorer に代表されるWWW閲覧ソフトウェア』のことですね。
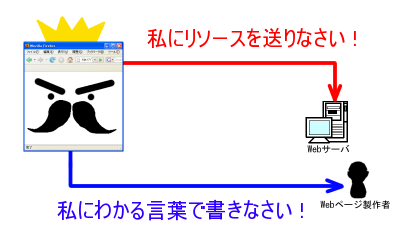
実は、このWebブラウザこそが、WWW界の王様なのです。というのも、以下のようにWebブラウザの機能次第で、インターネット上のリソース(資源、ファイル)を利用できるかどうかが決まるのです。
例えば、以下のようになっています。
- Webブラウザが理解できる形式 (URI) で表示したいリソース(ファイル)を指示しないと、インターネット上のリソース(ファイル)にアクセスできない
- Webブラウザが理解できる(記述)言語で書かれた文章やデータでないと、ブラウザ上で表示されない
- Webブラウザが理解できるプログラム言語で書かれたプログラムでないと、ブラウザ上で動作しない。
Webサーバ (Web Server, WWW Server)
基本的には、 『WWWのクライアント(Webブラウザ)から要求のあったリソース(ファイル)を、Webブラウザ(の動いているPC)へ送り出す機能をもっているサーバ』が、Webサーバ(WWWサーバ)です。
ただ最近では、Webサーバが複雑な処理をして、その処理結果をWebブラウザへ送り出すような場合も増えています。
例えば、熊大のSOSEKIのように、Webブラウザで入力されたデータをサーバに格納したり (SOSEKIで履修申告をするとサーバに登録されますよね)、Googleのように、検索対象の文字列を入力することで、Webサーバが対象となるサーバを探し出し、その文字列を含むWebページを列挙してくれるという具合です。
WWW動作の仕組み
前節の要素技術の組み合わせで、WWWは構築されています。
Webページを表示する仕組み(流れ)は、おおよそ以下のようになります。
- Webブラウザに、見たい(表示させたい)URIを入力する。もしくは、見たいリンクをクリックする。
- するとWebブラウザが(最終的にはWebブラウザの動いているPCが)、指示されたURI(リンクをクリックした場合はリンク先のURI)のサーバに対して、指定された手順(通常は「HTTP」)で、パスで示されたリソース(ファイル)を送ってくれるように要求を出す。
- 要求を受けたサーバは、送信要求を受けたファイルを指示を出したPC (「サーバ」に対して、「クライアント」と呼ぶこともある) に送信する。
- ファイルを受け取ったWebブラウザは、HTMLの文法に従いファイル中の文章をブラウザ画面にレイアウトする。
- 受け取ったHTMLファイルが文字情報しかないファイルであればこれで終りだが、他に画像ファイルや別の文書ファイルが必要であるファイルであれば、再度サーバにこれらのリソース(ファイル)を要求する。
- サーバから、それらのデータファイルが送られて来たら、HTMLの文法に従い、先の文字情報とともに最終的なレイアウトを行う。
このページのコンテンツには、Adobe Flash Player の最新バージョンが必要です。
![]()